-
[자료 구조] Data Structure - (2) Hash TableComputer Science 2019. 7. 11. 19:13
오늘은 자료 구조 중에서 매우 중요한 것들 중 하나인
Hash Table(해시테이블) 자료 구조에 대해서 정리해보려고 한다.
만약에 다음과 같은 친구들의 이름과 전화번호 리스트가 있다고 해보자.
1 Alice 010-1234-**** 2 Sam 010-1357-**** 3 Mike 010-1248-**** ... ... 10 Harry 010-9876-**** 이제 친구들의 이름, 전화번호 데이터를 어디엔가 저장해뒀다가 전화번호가 필요할 때마다
친구들의 이름을 입력해서 전화번호 데이터를 찾으려고 한다.
이 때 친구들의 전화번호를 가장 빠르게 찾기 위한 방법 중 하나가 바로 해시 테이블이다.
해시 테이블을 구성하는 데는 해시 함수(Hash function)라는 것이 필수적이다.
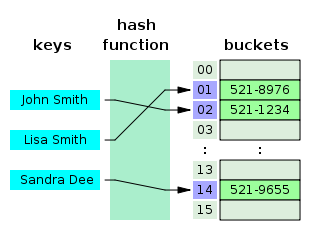
해시 함수는 친구 이름과 같은 문자열을 받아서 고유한 숫자키로 변경해주는 함수이다.
만약에 위 데이터를 해시 테이블로 구성하고 싶다면 다음과 같은 과정을 거치면 된다.
먼저 10개의 데이터를 넣을 것이기 때문에 10개의 공간을 준비한다.
Alice부터 차례대로 해시 함수에 넣어 고유한 숫자키를 받아낸다.
예를 들어 Alice의 숫자키는 3, Sam의 숫자키는 7, Mike의 숫자키는 1이라고 해보자.
이 때의 숫자키 값은 데이터 공간의 주소값이 된다.
0 1 2 3 4 5 6 7 8 9 010-1248-**** 010-1234-**** 010-1357-**** 그럼 이제 아까 준비한 공간에 숫자키를 방 번호로 삼아 전화번호 데이터를 집어넣는다.
이제 내가 Alice의 전화번호를 알고싶다면 복잡하게 loop을 돌리거나 할 필요없이
단지 Alice라는 이름을 해싱 함수에 넣고 숫자키를 알아낸 다음 그 방 번호의 데이터를 확인하면
아주 쉽게 Alice의 전화번호를 알아낼 수 있다.
Hash Table
Process your key through a hashing function which converts to an addressble space.
Since we cannot manage low level memory with javascript, we will just use an empty array.해시 테이블이란 위의 예시에서 살펴보았듯이 해시 함수(hash function)을 사용하여 키 값을 데이터 공간의 주소로 변환하고 해당 주소에 키 값에 대응하는 데이터를 넣는 자료 구조를 말한다.
hash table의 장점
- 중복 데이터를 찾아내기 쉬움
- 빠른 탐색, 삽입, 삭제 속도
- 어떤 항목과 다른 항목의 관계를 모형화하기 좋음
단순 리스트에 저장한 데이터는 중복된 데이터를 찾기 위해서 단순 탐색을 계속해서 반복해야하기 때문에 성능이 매우 좋지 않다. 그러나 해시 테이블에 저장하면 데이터가 있는지 순간적으로 알려주기 때문에 중복 확인하는 것이 매우 쉬워진다.
hash table의 단점
- Not suitable for ordered data
- Might need large space allocation (공간 효율성이 낮음)
- Must have a good hash function
해시 테이블의 가장 큰 단점은 공간 효율성이 낮다는 것이다. 아까도 보았듯이 10개의 자료를 넣기 위해 미리 빈 공간을 만든 다음 2개의 데이터만 넣는다면 8개의 공간이 빈 상태가 된다. 만약에 처음에 10개의 데이터를 넣고 싶어서 10개의 공간을 만들었다가 11개의 공간을 넣게 되면 overflow가 발생하기 때문에 데이터 공간을 크게 늘이고 기존의 데이터를 다시 재해싱해야 한다. 그 과정이 비효율적이기 때문에 대개의 경우 내가 삽입할 자료의 크기보다 훨씬 큰 데이터 공간을 미리 만들고 시작하기 때문에 공간 효율성이 낮아진다.
또한 해시 테이블은 정렬된 데이터를 다루기 적절하지 않은 구조이며 해시 함수에 대한 의존도가 매우 높다. 만약에 해시 함수의 성능이 매우 떨어지거나 해시 함수가 원하는대로 작동하지 않는다면 그 해시 테이블의 성능과 효율도 매우 나빠질 것이다.
Collision
해시 테이블은 위에서도 확인했듯이 매우 성능이 뛰어난 자료 구조이다. 충돌이 발생하기 전까진 말이다.
해시 테이블의 충돌이란 다른 키 2개를 해시 함수에 넣었는데 같은 주소 값이 나오는 경우를 말한다.
예를 들어 Alice와 Sam이란 키값을 해시 함수에 넣었는데 둘 다 5라는 주소값이 나오는 경우이다.
좋은 해시 함수를 쓸 수록 충돌이 발생할 확률이 낮아지게 되지만
많은 양의 데이터를 처리하다보면 충돌이 발생하는 경우가 생길 수 밖에 없다.
충돌이 발생할 때 해결하는 방법은 여러 가지가 있지만 가장 대표적인 방법으로는 2가지가 있다.
하나는 Linked List 방법이다.

같은 주소가 나왔을 때 해당 주소에 이미 데이터가 있다면 그 데이터에 연결 리스트로 연결하는 방법이다.
만약에 예를 들어서 알파벳을 각각 0~25의 숫자에 대응시킨 후,
영어 단어를 입력하면 맨 앞글자에 따라 해당 숫자를 output으로 넘겨주는 해싱 함수가 있다고 해보자.
위 해시 함수를 사용하여 전화번호 해시 테이블을 만들면
A로 시작하는 이름을 가진 친구는 전부 같은 주소값을 갖게 될 것이다.
이 경우에 해당 주소에 A로 시작하는 친구의 데이터를 연결 리스트로 모두 연결하면 된다.
이 방법의 단점은 충돌 횟수가 늘어나 연결 리스트의 길이가 길어질수록
해시 테이블의 성능이 매우 낮아진다는 것이다.
해시 테이블은 데이터를 빨리 찾고 삭제하고 입력할 수 있는 장점이 있는데
연결 리스트가 길어지면 연결 리스트를 순회하는 과정 탓에 성능이 떨어지게 된다.
다른 방법은 Linear probing(선형탐사)이다. 선형 탐사는 충돌이 발생한 지점의
다음 방부터 탐사하여 빈 방이 있으면 그 공간에 데이터를 집어넣는 방법이다.
만약 끝까지 탐색했는데 빈 공간이 없다면 맨 처음으로 돌아가 다시 검사한다.
매우 간단하지만 만약에 주변에 데이터 공간이 비어있지 않다면 빈 공간을 찾기 위해
모든 공간을 탐색해야 하는 단점이 있다.

Big O (when there is no collision)
- Insertion: O(1)
- Deletion: O(1)
- Search: O(1)
충돌이 일어나지 않았을 경우 해시 테이블은 매우 좋은 성능이 매우 좋은 편이다.
데이터를 추가할 때, 그저 해시 함수에 key를 넣어 주소를 알아낸 후 해당 주소에 데이터를 삽입하면 되기 때문에 O(1)의 상수 시간으로 표기할 수 있다. 데이터를 검색하거나 삭제할 때도 마찬가지이다.
여기서 상수 시간(constant time)이란 것은 순간적이라거나 연산이 한 번만 일어난다는 것이 아니다. 상수 시간은 해시 테이블의 크기와 상관없이 항상 똑같은 시간이 걸린다는 뜻이다.
예를 들어서 단순한 리스트에서 어떤 데이터를 단순탐색으로 찾으려면 앞에서부터 검색을 해야하므로 O(n) 만큼 소요된다. 이 때의 n은 리스트의 길이를 뜻한다. 만약 이진 탐색을 한다면 좀 더 빠르게 log 시간이 걸릴 것이다. 그러나 해시 테이블에서 데이터를 찾으면 테이블의 데이터가 1개이든 5개이든 1000개이든 크기와 아무 상관없이 데이터 하나를 꺼내는 시간은 모두 동일하다. 그러므로 평균적으로 해시 테이블은 아주 빠르다.
그러나 최악의 경우에 해시 테이블은 데이터의 탐색, 삽입, 삭제가 모두 O(n)만큼의 시간이 소요된다. 최악의 상황이 발생하지 않으려면 충돌을 최대한 피해야 하는데, 그러기 위해서는 좋은 해시 함수와 낮은 사용률이 필요하다.
Load Factor(사용률)
해시 테이블에서 사용률이란 해시 테이블의 공간을 얼마나 사용하고 있는지 수식으로 나타낸 것으로 다음과 같이 계산한다.

만약에 배열에서 5개의 방이 있는 데 그 중 2개의 공간에 데이터가 저장되어 있다면 2/5 = 0.4가 사용률이 된다.
만약에 저장할 데이터가 100개라면 해시 테이블에는 최소 100개의 공간이 있어야 한다. 만약 100개의 데이터에 100개의 공간이 있다면 해시 테이블의 사용률은 1이 된다.
만약 100개의 데이터가 있는데 공간이 50개밖에 없다면 사용률은 2가 되고 절반의 데이터는 공간이 없게 된다.
즉, 사용률이 1보다 크다는 것은 해시 테이블의 공간이 부족하다는 뜻이다.
대개의 경우 사용률이 0.7 이상으로 커지면 해시 테이블을 리사이징하는데 대략 2배 정도의 크기로 배열을 만든다.
리사이징을 하여 배열을 크게 만들고 나면 해시 함수를 사용하여 기존 테이블에 있던 데이터를
새로운 해시 테이블에 다시 저장해야한다. 이 과정은 시간이 매우 오래 걸리기 때문에 리사이징을 자주 하는 것은 좋지 않다.
What is hashing?
Taking an input string of any length and giving out an output of a fixed length
ex) MD5, SHA, ... and etc (유명한 해시 알고리즘 이름)
해싱이란 어떤 길이든지 상관없이 input string을 받아 고정된 길이의 결과물로 만들어주는 것이다.
비트코인도 SHA-256이란 해싱 알고리즘을 사용한다.
예를 들어서 SHA-256 해싱 알고리즘을 사용하면 아래 그림과 같은 결과가 나온다.

Hash Function
- Hash function needs to be idempotent.
A function given an input always outputs the same output.
해시 함수는 반드시 동일한 input이 들어가면 항상 동일한 output이 나와야 한다.
해시 함수를 사용할 때마다 매번 다른 결과가 나온다면 그 해시 테이블은 사용할 수가 없을 것이다.
-
Hash function needs to have a good distribution of values. 값이 골고루 분포되어야 한다.
해시 함수는 값이 골고루 분포되어야 한다. 만약 한 쪽으로 쏠려서 데이터가 분배되면 충돌이 자주 발생한다.
-
Hash function needs to be performant.
해시 함수는 성능이 뛰어나야 한다. 해시 함수의 성능은 해시 테이블의 성능과 직접적인 연관이 있기 때문이다.
Real Life Use Cases
- Address Book(주소록)
- Blockchain(블록체인)
- 자바스크립트 실행 엔진 (크롬, V8)
해시 테이블은 실생활에서 매우 많이 사용된다. 전화번호부나 주소록같은 경우가 대표적인 해시 테이블의 예시이다. 그 외에도 어떤 웹 사이트를 찾기 위해서 웹 사이트 주소를 브라우저에 입력한다고 해보자. 우리의 컴퓨터는 우리가 입력한 주소를 IP 주소로 변환한다.
GOOGLE.COM - 74.125.239.133
FACEBOOK.COM - 173.252.120.6
이런 식으로 말이다. 이런 과정을 DNS 확인(DNS resolution) 작업이라고 하는 데 이러한 작업에도 해시 테이블이 사용된다.
※ 참고서적:
Hello Coding 그림으로 개념을 이해하는 알고리즘, 마디트야 바르가바 지음, 한빛 미디어
반응형'Computer Science' 카테고리의 다른 글
[HTTP] HTTP Method 정리 / GET vs POST 차이점 (1687) 2019.09.10 [HTTP] Cross-Origin Resource Sharing (CORS)에 대하여 (609) 2019.09.10 [자료 구조] Data Structure - (3) Tree / Binary Search Tree (609) 2019.07.14 [자료 구조] Data Structure - (1) Stack / Queue / Linked List (968) 2019.07.08 [IT] 객체지향 프로그래밍이란? (2) 2019.04.25 COMMENT